一. 算法
求前面0的个数,我们最先想到的方式就是从第一位开始遍历,C语言代码很好写,也就是从软件上的算法很简单,只需要遍历判断的逻辑就可以统计出前0个数,但是这种遍历的方法很低效因为如果将这种串行的 for 循环直接映射到硬件电路上,会生成一种被称为行波结构的深度级联逻辑。 对于 1024 比特的超宽数据,串行结构意味着最坏情况下的关键路径需要依次穿过上千个逻辑门(如数据选择器 MUX)。这种结构的组合逻辑延迟时间复杂度为 O(N)。在极长的逻辑链路下,门延迟与线延迟的不断累加会导致电路的最高工作频率急剧下降,根本完全无法满足现代高速数字系统的时序要求。
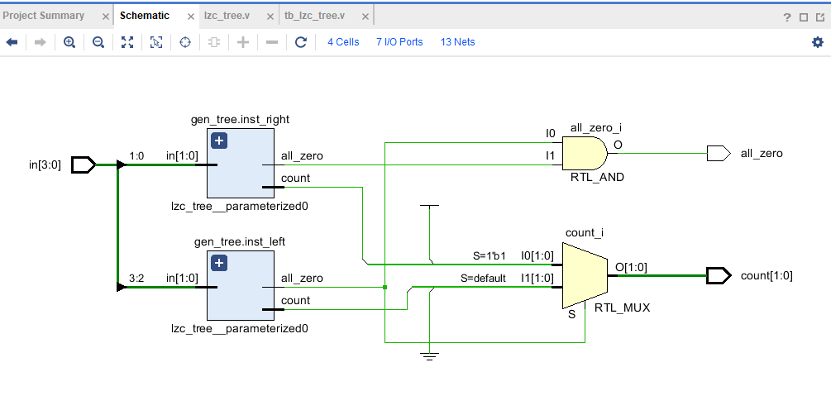
所以适合的算法应该是:二叉树分治,算法的核心在于将一个庞大的 1024-bit 查找问题,不断对半拆分,直到拆成最基础的 2-bit 单元,然后再逐级向上合并结果
二. 电路图Schematic

三. 数学与理论分析

四. Verilog代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
| `timescale 1ns / 1ps
// =============================================================================
// Module: lzc_tree (Leading Zero Counter Tree)
// Parameter: WIDTH - 输入数据的位宽 (必须是 2 的幂次方,如 2, 4, 8... 1024)
// COUNT_WIDTH - 计数输出的位宽,自动计算为 log2(WIDTH)
// =============================================================================
module lzc_tree #(
parameter WIDTH = 1024,
parameter COUNT_WIDTH = $clog2(WIDTH)
)(
input wire [WIDTH-1:0] in,
output wire [COUNT_WIDTH-1:0] count,
output wire all_zero
);
generate
// ---------------------------------------------------------------------
// Base Case: 2-bit 最底层叶子节点
// ---------------------------------------------------------------------
if (WIDTH == 2) begin : gen_base
// 如果高位和低位都是 0,则全零标志位置 1
assign all_zero = ~in[1] & ~in[0];
// 如果高位 in[1] 是 1,前导零个数为 0;
// 如果高位 in[1] 是 0,前导零个数为 1。
// (注意:如果 in 为 00,all_zero 为 1,此时 count 的值在上一级会被忽略,所以这里可以简化逻辑)
assign count[0] = ~in[1];
end
// ---------------------------------------------------------------------
// Recursive Case: 树的中间节点合并逻辑
// ---------------------------------------------------------------------
else begin : gen_tree
wire [COUNT_WIDTH-2:0] count_l, count_r;
wire az_l, az_r;
// 递归实例化左半部分(高位段)
lzc_tree #(
.WIDTH(WIDTH/2),
.COUNT_WIDTH(COUNT_WIDTH-1)
) inst_left (
.in(in[WIDTH-1 : WIDTH/2]),
.count(count_l),
.all_zero(az_l)
);
// 递归实例化右半部分(低位段)
lzc_tree #(
.WIDTH(WIDTH/2),
.COUNT_WIDTH(COUNT_WIDTH-1)
) inst_right (
.in(in[WIDTH/2-1 : 0]),
.count(count_r),
.all_zero(az_r)
);
// 【核心合并逻辑】
// 只有当左右两边全为零时,当前层级才全为零
assign all_zero = az_l & az_r;
// 巧妙的位拼接逻辑:
// 如果左半部分(高位)全是 0,说明前导零数量 = 左半边全长 + 右半边前导零。
// 在二进制中,这刚好等同于在最高位补 '1',拼接右半边的计数。
// 如果左半部分不全是 0,前导零在左边,直接在最高位补 '0',拼接左半边的计数。
assign count = az_l ? {1'b1, count_r} : {1'b0, count_l};
end
endgenerate
endmodule
|
五. 功能仿真图

六. 功能仿真结果分析
图中 error_count[31:0] 那一行,从头到尾都是一根笔直的低电平绿线(数值恒为 00000000)。这说明在我们写的比较器逻辑中,1024 位的海量随机测试和极端边界测试,没有发生哪怕一次结果不匹配。
对比一下 count[9:0] 和 expected_count[9:0] 这两行的波形。你会发现无论是方框的长短,还是数据跳变的时间点,两者在视觉上完全一模一样,如同倒影。这就证明硬件电路的结果紧紧咬住了软件算出的正确答案。
屏幕最左侧(0 ns 到 10 ns 的位置),all_zero 和 expected_all_zero 都有一个小小的脉冲凸起(高电平)。回忆一下我们在 Testbench 里的代码: in = {WIDTH{1’b0}}; #10; // 第一项测试:全0 这个小小的凸起完美地证明了:在仿真的最初 10 纳秒内,输入是全零,电路正确地输出了“全零标志位”。10纳秒后,输入变成了全 1,标志位立刻降为 0。
七. Synthesis
 Path 1 是整个 1024-bit 树形电路中最长的数据通路。它的总延迟是 10.781 ns。Path 1 到 Path 10 的 Levels,数值全都是 9 或者 10。
Path 1 是整个 1024-bit 树形电路中最长的数据通路。它的总延迟是 10.781 ns。Path 1 到 Path 10 的 Levels,数值全都是 9 或者 10。
如果使用传统的 for 循环从高位到低位依次判断,对于 1024-bit 的数据,关键路径需要穿过约 1024 个数据选择器MUX,逻辑级数接近 O(N) 即 1024 级,延迟极其巨大,电路无法在时钟下工作。 而本设计采用了二叉树分治架构,将延迟的复杂度从 O(N)降维到了 O(\log_2 N)。理论上 1024-bit 的二叉树深度恰好为 log_2(1024) = 10 级。
如 Vivado 时序分析报告所示,经过逻辑综合后,最长关键路径(Path 1)的总延迟为 10.781 ns。其中最核心的逻辑级数实测为 9 级(部分路径为 10 级)。理论上树有 10 层,为什么 Vivado 综合出来有的是 9 级?因为 Xilinx 7系列 FPGA 的底层是由 6输入查找表(LUT6)构成的。综合工具在映射时,把最底层的 2-bit 单元和 4-bit 单元的逻辑合并到了同一个 LUT6 里面,从而将 10 级的组合逻辑进一步压缩成了 9 级。
八. 结论
二叉树架构成功将 1024 级的庞大延迟压缩至 9~10 级查找表延迟,在没有任何流水线寄存器切分的情况下,纯组合逻辑仅耗时不到 11 ns,极大提升了电路的最高工作频率